Machine Learning Model Drift: 4 Proactive Monitoring Strategies for 95% Performance

In the rapidly evolving landscape of artificial intelligence, machine learning models are no longer static entities; they are dynamic systems that operate within an ever-changing world. The challenge? Ensuring their continued accuracy and reliability over time. This is where the critical concept of ML Model Drift comes into play. As data distributions shift, user behaviors evolve, and underlying relationships change, even the most meticulously trained models can experience a decline in performance. This phenomenon, known as model drift, can silently erode the effectiveness of your AI systems, leading to flawed predictions, suboptimal decisions, and significant business impact.
Imagine a financial fraud detection system that was 99% accurate upon deployment. If the patterns of fraud evolve, and the model isn’t updated or monitored, its accuracy could plummet to 70% or even lower, allowing sophisticated fraudulent transactions to slip through undetected. Similarly, a recommendation engine that once delighted users with hyper-personalized suggestions might start offering irrelevant content if user preferences shift and the model fails to adapt. The consequences are clear: reduced customer satisfaction, lost revenue, and damaged reputation.
The imperative, therefore, is not just to build robust machine learning models, but to implement equally robust strategies to monitor and mitigate ML Model Drift. Our goal for 2026 and beyond is ambitious yet achievable: to maintain at least 95% performance in deployed ML models. This article will delve into four proactive monitoring strategies that are essential for detecting, understanding, and addressing model drift before it significantly impacts your operations. By embracing these strategies, organizations can ensure their AI investments continue to deliver maximum value, remaining agile and responsive to the dynamic nature of real-world data.
Understanding ML Model Drift: The Silent Performance Killer
Before we dive into proactive strategies, it’s crucial to thoroughly understand what ML Model Drift entails and why it’s such a pervasive problem in the machine learning lifecycle. Model drift, at its core, refers to the degradation of a machine learning model’s predictive performance due to changes in the underlying data distributions or the relationships between input features and the target variable over time. It’s an inevitable reality in most real-world applications where data is constantly evolving.
Types of Model Drift
To effectively combat model drift, we must first recognize its different manifestations:
- Concept Drift: This occurs when the relationship between the input features and the target variable changes. For example, in a spam detection model, the definition of ‘spam’ might evolve as spammers develop new techniques, making previously effective features less indicative of spam. The underlying concept that the model learned has shifted.
- Data Drift (or Covariate Shift): This refers to changes in the distribution of the input features themselves, while the relationship between features and the target variable might remain the same. For instance, if a model was trained on customer demographics from one region and is then deployed in another with a significantly different demographic profile, data drift has occurred. Another example could be changes in sensor readings due to environmental factors or equipment degradation, leading to input data distributions that deviate from the training data.
- Label Drift (or Prior Probability Shift): This type of drift happens when the distribution of the target variable changes over time, independent of the input features. For example, in a medical diagnosis model, if a new disease emerges or an existing one becomes more prevalent, the base rate of positive diagnoses (the label) will shift, even if the symptoms (features) remain the same. This can significantly impact models that rely on the prior probabilities of classes.
- Feature Drift: A specific form of data drift where individual feature distributions change. This can be due to changes in data collection methods, sensor calibration issues, or external factors influencing specific data points.
Each type of drift requires a slightly different approach to detection and mitigation. Understanding these nuances is the first step toward building a resilient ML system.
Why is ML Model Drift Inevitable?
The dynamic nature of the real world ensures that ML Model Drift is not a matter of ‘if’ but ‘when’. Several factors contribute to this inevitability:
- Evolving User Behavior: User preferences, purchasing habits, and online interactions are constantly changing, impacting recommendation systems, marketing campaigns, and fraud detection.
- Economic and Societal Changes: Economic downturns, technological advancements, regulatory shifts, and even global pandemics can drastically alter data patterns and relationships.
- Seasonal and Cyclical Patterns: Many datasets exhibit seasonal variations (e.g., holiday shopping, weather patterns) that, if not properly accounted for, can cause models to drift during off-peak times.
- Data Collection Changes: Updates to data pipelines, sensor upgrades, or changes in data entry protocols can alter the distribution of input features.
- Adversarial Attacks: In some domains, malicious actors actively try to exploit model weaknesses, leading to rapid and intentional drift in data patterns.
- Feedback Loops: The model’s own predictions can influence future data, creating complex feedback loops that accelerate drift. For instance, a recommendation system might inadvertently narrow user exposure, changing their preferences over time.
Given these complexities, a proactive and continuous monitoring strategy for ML Model Drift is not a luxury, but a fundamental requirement for maintaining high-performing machine learning systems.
Strategy 1: Robust Data Monitoring and Validation Pipelines
The first line of defense against ML Model Drift lies in vigilant monitoring of the data itself. Since drift originates from changes in data, establishing robust data monitoring and validation pipelines is paramount. This strategy focuses on detecting shifts in input data distributions and ensuring data quality before it even reaches the model for inference.
Monitoring Input Data Distributions
A significant cause of model degradation is data drift, where the statistical properties of the input features change over time. Proactive monitoring involves tracking key statistical metrics for each feature in your input data stream and comparing them against the distributions observed during training or a recent stable period.
- Statistical Tests: Employ statistical tests to compare distributions. For continuous features, the Kullback-Leibler (KL) divergence, Jensen-Shannon (JS) divergence, or Population Stability Index (PSI) can quantify the difference between current and baseline distributions. For categorical features, chi-squared tests or G-tests are suitable.
- Descriptive Statistics: Continuously monitor fundamental descriptive statistics such as mean, median, standard deviation, variance, skewness, and kurtosis for numerical features. For categorical features, track the frequency counts and proportions of each category. Sudden significant shifts in these metrics can signal data drift.
- Feature-Level Alerts: Set up automated alerts that trigger when a monitored statistic for a particular feature deviates beyond a predefined threshold (e.g., a 10% change in mean, or a PSI score exceeding 0.1). These alerts should be routed to data scientists or MLOps engineers for investigation.
Data Quality and Integrity Checks
Beyond statistical distributions, the quality and integrity of incoming data are critical. Corrupted, incomplete, or incorrectly formatted data can lead to erroneous model predictions and mask underlying drift issues.
- Missing Value Rates: Track the percentage of missing values for each feature. An unexpected increase can indicate issues in data collection or preprocessing pipelines.
- Outlier Detection: Implement anomaly detection algorithms to identify extreme values in the input data. While some outliers are natural, a sudden influx can be a sign of data corruption or a significant, unhandled shift in the data generation process.
- Schema Validation: Ensure that the incoming data conforms to the expected schema (data types, column names, ranges). Any deviation should trigger an immediate alert, as it can break the model’s input expectations.
- Referential Integrity: For models relying on data from multiple sources, verify referential integrity where applicable, ensuring relationships between datasets remain consistent.
Establishing a Data Baseline
To effectively detect drift, you need a reliable baseline. This baseline typically consists of the statistical properties and distributions of the training data, or data from a recent period when the model was known to be performing optimally. Regularly update this baseline to reflect natural, expected evolution in data, but ensure these updates are deliberate and controlled.
By implementing these robust data monitoring and validation pipelines, organizations can catch early warning signs of ML Model Drift, preventing small inconsistencies from escalating into major performance degradation.
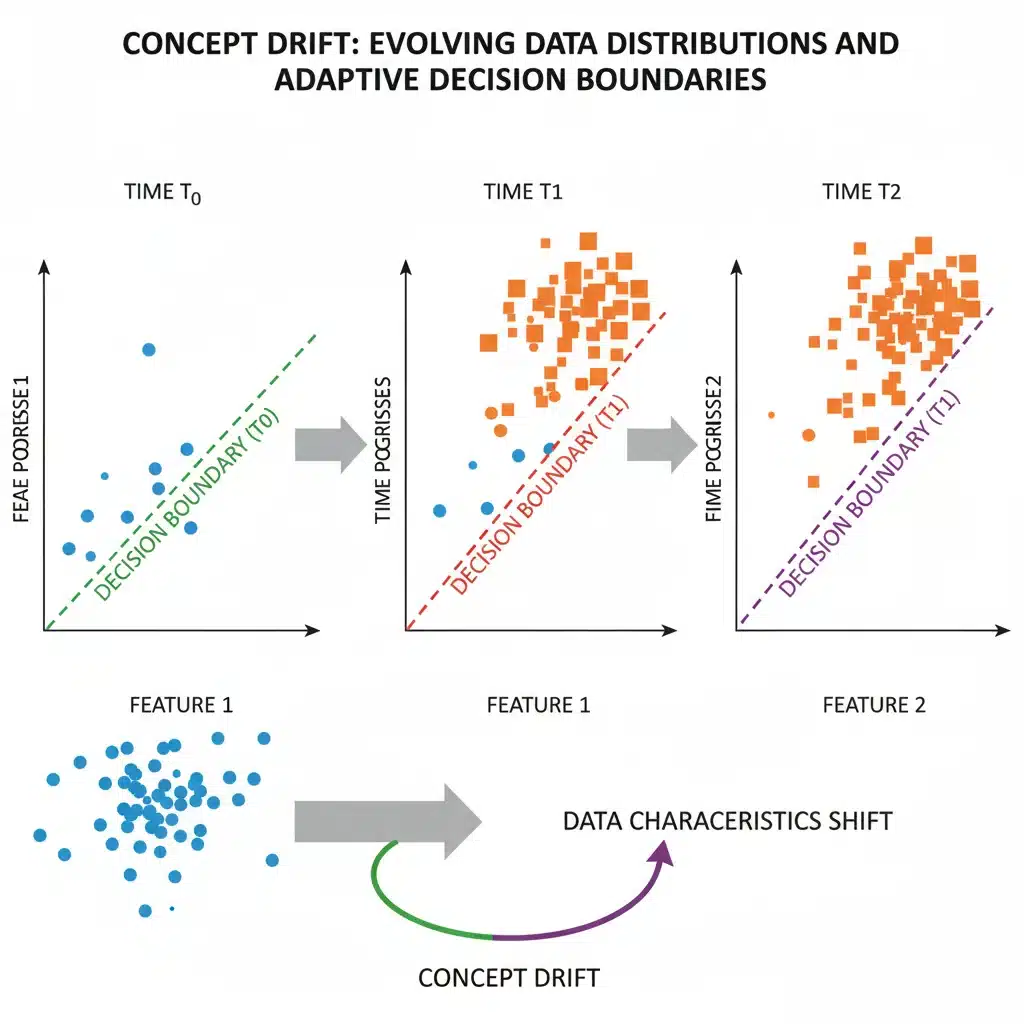
Strategy 2: Continuous Model Performance Monitoring
While data monitoring is crucial, it’s not sufficient on its own. The ultimate goal is to maintain model performance, and sometimes, even subtle changes in data can have a disproportionate impact on predictions. Therefore, continuous monitoring of the model’s actual performance metrics is indispensable for tackling ML Model Drift.
Monitoring Key Performance Indicators (KPIs)
The core of this strategy involves tracking the same metrics used during model training and evaluation, but now in a production environment. The specific KPIs will vary depending on the model type and business objective:
- Classification Models: Accuracy, Precision, Recall, F1-score, AUC-ROC, log-loss. It’s often more informative to monitor these metrics per class, especially if the classes are imbalanced.
- Regression Models: Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R-squared.
- Ranking Models: Normalized Discounted Cumulative Gain (NDCG), Mean Average Precision (MAP).
- Clustering Models: Silhouette Score (though often harder to monitor continuously without ground truth).
The challenge here is often the availability of ground truth labels in real-time. For many applications, labels are only available with a significant delay. This necessitates a multi-pronged approach, combining immediate proxy metrics with delayed true performance metrics.
Proxy Metrics for Early Drift Detection
When ground truth labels are delayed, proxy metrics can provide early indications of ML Model Drift:
- Prediction Distribution Shift: Monitor the distribution of your model’s outputs (e.g., predicted probabilities for classification, predicted values for regression). A significant shift in these distributions compared to a baseline can indicate that the model is behaving differently, even before ground truth is available.
- Prediction Volatility: Track how stable your model’s predictions are over time for similar inputs. Increased volatility could suggest the model is becoming less confident or less consistent.
- Model Confidence: For models that output confidence scores, monitor their distribution. A drop in average confidence or a shift towards less confident predictions can be an early warning sign.
- Uncertainty Estimates: For models capable of providing uncertainty estimates (e.g., Bayesian neural networks), monitor these metrics. An increase in uncertainty could correlate with drift.
Establishing Performance Baselines and Thresholds
Similar to data monitoring, establishing clear performance baselines is critical. This baseline should reflect the model’s expected performance during a period when it was known to be working well. Define acceptable performance degradation thresholds (e.g., a 5% drop in F1-score) that will trigger automated alerts. These thresholds should be carefully calibrated with domain experts to reflect business tolerance for error.
A/B Testing for Model Updates
When you suspect ML Model Drift and deploy a retrained or new model, A/B testing is an invaluable strategy. By directing a portion of traffic to the new model and comparing its performance against the existing one, you can confirm whether the new model genuinely addresses the drift and improves performance without introducing new issues. This controlled experimentation minimizes risk and provides empirical evidence of improvement.
By combining direct performance monitoring with intelligent proxy metrics and controlled experimentation, organizations can proactively identify and respond to performance degradation caused by ML Model Drift, maintaining high levels of accuracy and reliability.
Strategy 3: Feature Attribution and Explainability Monitoring
Understanding why a model makes certain predictions is becoming as important as the predictions themselves. When it comes to ML Model Drift, monitoring feature attribution and model explainability can provide crucial insights into how the model’s internal logic is changing, even if overall performance metrics haven’t yet dipped significantly. This strategy helps diagnose the root cause of drift and guides effective mitigation.
Tracking Feature Importance Over Time
The relative importance of different features to your model’s predictions can shift as underlying data dynamics change. Monitoring these shifts can reveal concept drift or data drift impacting specific features.
- Global Feature Importance: Techniques like SHAP (SHapley Additive exPlanations) values or permutation importance can be used to calculate the overall importance of each feature to the model’s predictions. Track these values over time. A significant change in the ranking or magnitude of feature importance can signal that the model is relying on different signals than it used to, or that the importance of previous signals has diminished.
- Local Feature Importance (SHAP/LIME): For individual predictions, LIME (Local Interpretable Model-agnostic Explanations) or SHAP can explain which features contribute most to that specific outcome. While computationally intensive to monitor for every prediction, sampling these explanations over time can reveal patterns of how the model’s reasoning changes for different segments of data.
- Alerting on Feature Importance Shifts: Set up alerts if the importance of a key feature drops below a certain threshold or if a previously unimportant feature suddenly becomes highly influential. This can point to an area where data or concept drift is occurring.
Monitoring Model Behavior with Explainable AI (XAI)
XAI techniques offer a window into the model’s decision-making process. By continuously analyzing these explanations, you can detect subtle changes in how the model interprets inputs.
- Partial Dependence Plots (PDPs) and Individual Conditional Expectation (ICE) Plots: Generate and compare PDPs and ICE plots for key features at regular intervals. These plots show the marginal effect of one or two features on the predicted outcome. If the shape or slope of these plots changes significantly, it indicates that the model’s learned relationship for that feature has drifted.
- Counterfactual Explanations: These explanations identify the smallest change to an input that would alter the model’s prediction. Monitoring the types of counterfactuals generated over time can reveal how the model’s decision boundaries are shifting. If the ‘required change’ to flip a prediction becomes drastically different, it’s a strong indicator of drift.
- Adversarial Examples Detection: While not strictly drift detection, an increase in the number of successful adversarial examples can indicate that the model’s robustness or understanding of its input space is deteriorating, which can be a symptom of underlying drift.
Segmented Analysis of Explanations
Often, ML Model Drift doesn’t affect all segments of your data equally. By analyzing feature attributions and XAI explanations for specific data segments (e.g., different customer groups, geographic regions, or product categories), you can pinpoint where the drift is most pronounced and understand its specific impact.
For example, if a model for predicting loan defaults shows a stable feature importance for older demographics but a significant shift in how it weighs income for younger applicants, it indicates localized drift that requires targeted investigation and potential retraining on that specific segment.
By integrating feature attribution and explainability monitoring into your MLOps pipeline, you move beyond just knowing that drift is happening to understanding why it’s happening, enabling more targeted and effective mitigation strategies.
Strategy 4: Automated Retraining and Model Versioning
Even with the most sophisticated monitoring in place, ML Model Drift will eventually necessitate action. The final proactive strategy involves establishing an automated, robust process for model retraining and versioning. This ensures that your models can adapt to evolving data environments with minimal manual intervention and maximum control.
Automated Retraining Triggers
The monitoring strategies discussed previously should feed directly into an automated retraining pipeline. Alerts generated from data drift, performance degradation, or shifts in feature importance should serve as triggers for retraining.
- Threshold-Based Retraining: When a key performance metric (e.g., F1-score) drops below a predefined threshold, or a data distribution metric (e.g., PSI) exceeds a certain value, automatically initiate a retraining job.
- Time-Based Retraining: For some applications, a periodic retraining schedule (e.g., weekly, monthly, quarterly) might be sufficient, especially if drift is known to be gradual and predictable. This acts as a safety net even if explicit drift isn’t immediately detected by other means.
- Event-Based Retraining: Certain external events (e.g., a major product launch, a significant policy change, a global economic shift) can be known triggers for potential drift. Set up mechanisms to manually or programmatically initiate retraining in response to such events.
The retraining process should be fully automated, from data fetching and preprocessing to model training, evaluation, and deployment. This minimizes human error and ensures rapid response to drift.
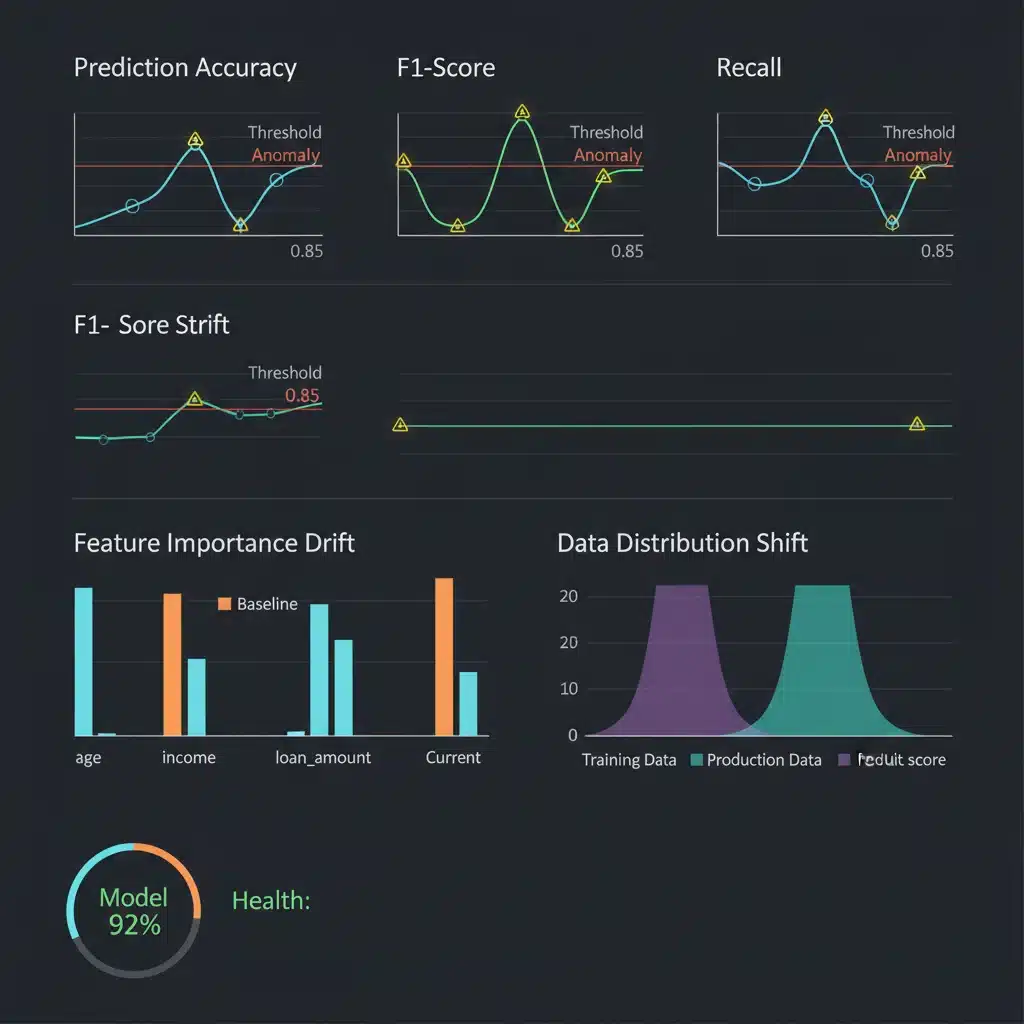
Continuous Integration/Continuous Deployment (CI/CD) for ML (MLOps)
Integrating retraining into an MLOps CI/CD pipeline is crucial. This involves:
- Automated Data Pipelines: Ensure a continuous flow of fresh, validated data for retraining.
- Version Control for Code and Data: Track all changes to model code, training scripts, and even datasets. This allows for reproducibility and rollbacks if a new model version performs worse.
- Automated Model Evaluation: Before a retrained model is deployed, it must undergo rigorous automated evaluation against a held-out test set and, ideally, against the current production model.
- Shadow Deployment/A/B Testing: New model versions should ideally be deployed in a shadow mode (running in parallel without impacting live predictions) or through A/B testing to ensure they outperform the existing model before a full rollout.
- Automated Rollback: If a newly deployed model performs poorly or introduces unexpected issues, an automated rollback mechanism to the previous stable version is essential.
Model Versioning and Governance
Maintaining a clear record of all model versions is vital for auditing, debugging, and understanding the evolution of your AI systems.
- Model Registry: Implement a model registry that stores metadata for each model version, including training data used, hyperparameters, performance metrics, deployment date, and the reason for retraining.
- Reproducibility: Ensure that any model version can be fully reproduced, from the exact code and data used to its training environment. This is critical for investigating past performance issues or regulatory compliance.
- Documentation: Maintain comprehensive documentation for each model, including its intended use, limitations, and key assumptions. This helps manage expectations and facilitates knowledge transfer.
Automated retraining and robust model versioning form the backbone of a resilient MLOps strategy, allowing organizations to continuously adapt to ML Model Drift and maintain high performance without constant manual intervention. This strategy transforms drift from a crisis into a manageable, routine part of the ML lifecycle.
Implementing a Holistic ML Drift Strategy for 95% Performance by 2026
Achieving and sustaining over 95% performance in your machine learning models by 2026, despite the omnipresent threat of ML Model Drift, requires a holistic and integrated approach. It’s not enough to implement one or two of these strategies; their combined power creates a robust defense system against the unpredictable nature of real-world data.
The Interconnectedness of Strategies
- Data Monitoring informs Performance Monitoring: Shifts in input data (Strategy 1) are often precursors to performance degradation (Strategy 2). Detecting data drift early allows for preventative action before accuracy significantly drops.
- Performance Monitoring Triggers Explainability Analysis: When performance metrics decline, leveraging feature attribution and XAI (Strategy 3) helps pinpoint the exact cause of the drift, guiding more effective retraining or data remediation.
- Explainability Guides Retraining: Understanding which features have drifted or how the model’s internal logic has changed provides critical insights for feature engineering, data collection priorities, or even architectural changes during automated retraining (Strategy 4).
- Automated Retraining Validates Monitoring: A successful automated retraining cycle validates the effectiveness of your drift detection mechanisms and ensures the continuous relevance of your monitoring thresholds.
Key Considerations for Implementation
- Tooling and Infrastructure: Invest in MLOps platforms and tools that support automated data validation, performance dashboards, drift detection algorithms, model registries, and CI/CD pipelines. Open-source tools (e.g., Evidently AI, MLflow, Seldon Core) and commercial offerings (e.g., Datadog, AWS SageMaker, Google Cloud AI Platform) can streamline these processes.
- Cross-Functional Teams: Effective drift management requires collaboration between data scientists, ML engineers, DevOps engineers, and domain experts. Data scientists understand the model and its nuances, ML engineers build and maintain the pipelines, and domain experts provide critical context for interpreting drift and its business implications.
- Scalability: As your portfolio of ML models grows, your drift monitoring and mitigation strategies must scale. Automate as much as possible to avoid becoming a bottleneck.
- Cost-Benefit Analysis: While proactive monitoring requires upfront investment, the cost of undetected model drift (e.g., fraudulent transactions, lost customers, incorrect medical diagnoses) far outweighs the cost of prevention. Quantify the potential impact of drift to justify resource allocation.
- Adaptive Thresholds: Fixed thresholds for drift detection may not always be optimal. Consider implementing adaptive thresholds that adjust based on historical data, seasonality, or expected variance, reducing alert fatigue while remaining sensitive to true drift.
By embracing these four proactive strategies – robust data monitoring, continuous performance monitoring, explainability analysis, and automated retraining with versioning – organizations can transform the challenge of ML Model Drift into a competitive advantage. It ensures that machine learning models remain accurate, reliable, and valuable assets, driving intelligent decisions and sustained innovation well into 2026 and beyond. The future of AI success hinges not just on building powerful models, but on diligently nurturing and adapting them in the face of an ever-changing world.
Conclusion
The journey to maintaining 95% performance in machine learning models is continuous, demanding constant vigilance and adaptability. ML Model Drift is an inherent characteristic of dynamic systems, but it is not an insurmountable obstacle. By systematically implementing the four proactive strategies outlined in this article – robust data monitoring, continuous model performance tracking, insightful feature attribution, and automated retraining coupled with diligent versioning – organizations can build resilient AI systems that withstand the test of time and evolving data. The commitment to these practices transforms potential model degradation into opportunities for continuous improvement, ensuring that your AI investments consistently deliver high-impact results and competitive advantage. Proactive drift management is not merely a technical task; it’s a strategic imperative for any enterprise serious about leveraging machine learning to its fullest potential in the coming years.
")




