Mastering Federated Learning: Data Privacy & Cost Savings in AI 2025

Federated learning is revolutionizing AI development by enabling collaborative model training across decentralized datasets, significantly boosting data privacy and reducing training costs by an estimated 15% for 2025 AI models.
As the digital landscape evolves, the demand for sophisticated AI models grows, bringing with it complex challenges, particularly regarding data privacy and operational costs. Federated learning strategies are emerging as a pivotal solution, promising to reshape how AI is developed and deployed. This innovative approach allows organizations to collaboratively train robust AI models without ever centralizing sensitive user data, a game-changer for privacy and efficiency.
Understanding the Core of Federated Learning
Federated learning is a decentralized machine learning approach that trains algorithms on local data samples contained in local nodes without explicitly exchanging data samples. Instead of sending raw data to a central server, only model updates or parameters are shared. This fundamental shift offers significant advantages, especially for industries dealing with highly sensitive information.
The concept bypasses many traditional data governance hurdles by keeping data where it originates. This means that personal healthcare records, financial transactions, or proprietary business data can contribute to powerful AI models without ever leaving their secure environments. The aggregate knowledge gleaned from these local models then informs a global model, leading to enhanced collective intelligence without compromising individual data sovereignty.
The Decentralized Training Paradigm
- Local Model Training: Each participating device or server trains a local model using its own dataset. This training occurs entirely on the device, ensuring data remains private.
- Parameter Aggregation: Only the learned parameters or model updates, not the raw data, are sent to a central server. This server aggregates these updates from numerous participants.
- Global Model Update: The central server then uses these aggregated updates to improve a global model, which is subsequently sent back to the local devices for further refinement. This iterative process allows the global model to learn from diverse datasets without direct access.
This iterative cycle not only safeguards privacy but also opens doors for collaboration among entities that might otherwise be unable to share data due to regulatory or competitive concerns. The promise of federated learning extends beyond mere compliance; it fosters a new era of collaborative AI development.
In essence, federated learning represents a paradigm shift from a centralized data processing model to a decentralized one, where privacy is built into the architecture. By enabling local training and global aggregation of model updates, it provides a robust framework for developing powerful AI solutions while adhering to stringent data protection standards.
Enhanced Data Privacy through Federated Learning
One of the most compelling benefits of federated learning is its inherent ability to bolster data privacy. In an age where data breaches are common and regulations like GDPR and CCPA are increasingly strict, traditional AI training methods that require centralized data collection pose significant risks. Federated learning directly addresses these concerns by keeping sensitive data localized.
By training models on device, the raw data never leaves its source. This significantly reduces the attack surface for malicious actors, as there is no single point of failure where a large trove of sensitive information could be compromised. Instead, an attacker would need to breach countless individual devices, a far more complex and resource-intensive task.
Minimizing Data Exposure Risks
- No Raw Data Transfer: The most critical aspect is that actual user data is never transmitted to a central server. Only encrypted model updates or statistical summaries are exchanged.
- Differential Privacy Integration: Federated learning can be combined with techniques like differential privacy, which adds a small amount of noise to the model updates. This further obscures individual contributions, making it nearly impossible to infer specific data points from the aggregated model.
- Secure Aggregation Protocols: Advanced cryptographic methods, such as secure multi-party computation (SMC) or homomorphic encryption, can be employed to ensure that the central server cannot even inspect individual model updates, only the aggregated result.
These privacy-preserving mechanisms are not merely add-ons; they are integral to the design philosophy of federated learning. They transform the AI development process from one that inherently risks privacy to one that actively protects it. This proactive approach to data security is becoming indispensable for organizations operating in highly regulated sectors such as healthcare, finance, and government.
The ability to train AI models on distributed, private datasets without ever pooling the raw information is a monumental step forward. It allows for the development of highly accurate and robust AI systems that respect user privacy, fostering greater trust and enabling broader adoption of AI technologies across various sensitive applications.
Reducing Training Costs for 2025 AI Models
Beyond privacy, federated learning also offers substantial economic advantages, particularly in reducing the operational costs associated with training large-scale AI models. Traditional centralized training often incurs significant expenses related to data storage, transfer, and the computational infrastructure required to process massive datasets in one location.
For 2025 AI models, which are expected to be even more complex and data-hungry, these costs could become prohibitive for many organizations. Federated learning mitigates these financial burdens by distributing the computational load and minimizing the need for extensive data centralization efforts.
Economic Efficiencies in AI Development
- Lower Data Transfer Costs: Instead of moving petabytes of raw data to a central cloud, only smaller model updates are transmitted. This drastically cuts down on network bandwidth and associated costs.
- Distributed Computing Power: Training occurs on local devices, leveraging existing computational resources that might otherwise be underutilized. This reduces the need for massive, centralized GPU clusters, which are expensive to acquire and maintain.
- Reduced Storage Requirements: Central servers no longer need to store vast amounts of raw data, leading to significant savings on data storage infrastructure and compliance.
By shifting the computational burden to the edge, federated learning makes AI development more accessible and cost-effective. Organizations can tap into a wider pool of data without the overhead of building and maintaining colossal data centers dedicated solely to AI training. This democratizes AI, allowing smaller entities or those with limited budgets to participate in advanced model development.
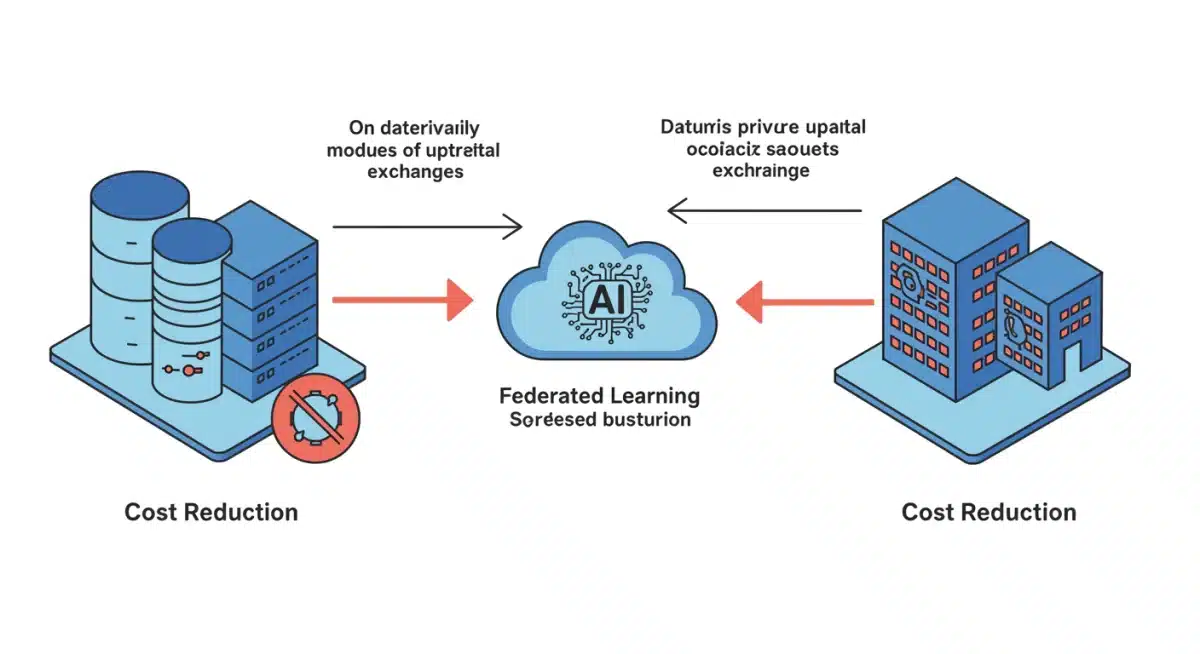
Estimates suggest that adopting federated learning could lead to a 15% reduction in overall training costs for AI models by 2025. This saving is critical for fostering innovation and making advanced AI more attainable for a broader range of applications and industries.
Key Strategies for Implementing Federated Learning
Successfully deploying federated learning requires a strategic approach that addresses both technical and organizational aspects. It’s not merely about adopting a new algorithm but fundamentally rethinking data governance, model development workflows, and collaborative paradigms. Organizations must carefully consider their infrastructure, data distribution, and security protocols.
One crucial strategy involves selecting the right aggregation algorithm. While simple averaging is often used, more sophisticated methods like Federated Averaging (FedAvg) or its variants can improve model convergence and robustness. The choice depends heavily on the heterogeneity of local datasets and the desired performance characteristics.
Strategic Implementation Considerations
- Robust Security Protocols: Implement end-to-end encryption for all model updates and explore secure aggregation techniques like secure multi-party computation to protect updates during transmission and aggregation.
- Client Selection Mechanisms: Develop intelligent strategies for selecting which clients participate in each training round. This can involve prioritizing clients with diverse data, sufficient computational resources, or those that haven’t participated recently to ensure fair representation and efficient training.
- Handling Data Heterogeneity: Address statistical challenges arising from non-IID (non-independent and identically distributed) data across clients. Techniques like local weight regularization or personalized federated learning can help improve model performance in heterogeneous environments.
Another important strategy is to design an effective incentive mechanism for client participation. Since clients contribute their local computational resources and data (indirectly, through updates), providing incentives—whether monetary, access to improved models, or other benefits—can encourage sustained engagement. Clear communication about the benefits of participation, both for the individual and the collective, is also vital.
Ultimately, successful implementation hinges on a holistic view that integrates technical innovation with sound governance and a clear understanding of stakeholder motivations. This ensures that the benefits of privacy and cost reduction are fully realized while maintaining high model performance.
Challenges and Future Outlook for Federated AI
While federated learning presents a compelling vision for the future of AI, it is not without its challenges. The distributed nature of the training process introduces complexities that traditional centralized methods do not encounter. Addressing these challenges is crucial for the widespread adoption and continued evolution of federated AI.
One significant hurdle is the statistical heterogeneity of data across different clients. Real-world data is rarely uniformly distributed, meaning different devices might have vastly different data patterns. This non-IID data can lead to slower convergence rates and degrade the performance of the global model compared to a scenario with perfectly distributed data.
Another challenge lies in communication overhead. Even though only model updates are sent, coordinating thousands or millions of devices can still generate substantial network traffic. Optimizing communication protocols and developing efficient compression techniques for model updates are ongoing areas of research.
Overcoming Federated Learning Obstacles
- Mitigating Data Skew: Researchers are actively developing advanced aggregation algorithms and personalized federated learning techniques to handle non-IID data more effectively, ensuring robust model performance across diverse client datasets.
- Optimizing Communication: Innovations in sparse model updates, quantization, and communication-efficient optimization algorithms are reducing network bandwidth requirements, making federated learning more practical for large-scale deployments.
- Ensuring Robustness Against Malicious Clients: Developing mechanisms to detect and mitigate the impact of malicious clients who might attempt to poison the global model or infer private data from updates is a critical security challenge.
Despite these challenges, the future outlook for federated AI is incredibly promising. As research progresses and new techniques emerge, many of these obstacles are being systematically addressed. We can anticipate more sophisticated aggregation algorithms, enhanced privacy-preserving mechanisms, and more robust frameworks for managing diverse client populations.
The convergence of federated learning with other emerging technologies, such as edge computing and blockchain, is also expected to unlock new possibilities. This synergy could lead to even more secure, efficient, and decentralized AI systems, further solidifying federated learning’s role as a cornerstone of responsible AI development in the coming years.
Impact on Various Industries by 2025
By 2025, federated learning is poised to significantly impact a multitude of industries, transforming how they leverage AI while adhering to stringent privacy standards and optimizing operational costs. Its ability to train models on decentralized data makes it particularly attractive for sectors handling sensitive information or operating with geographically dispersed datasets.
In healthcare, federated learning can enable the development of more accurate diagnostic tools and personalized treatment plans by training AI models on vast, distributed patient data from hospitals and clinics, all without compromising individual patient privacy. This can lead to breakthroughs in disease detection and drug discovery.
Industry-Specific Applications and Benefits
- Healthcare: Facilitates collaborative research on medical imaging, electronic health records, and genomic data, leading to better diagnostic models and drug discovery, all while maintaining patient confidentiality.
- Finance: Enhances fraud detection and risk assessment models by allowing banks to share insights from their transaction data without revealing individual customer information, thus improving security across the financial ecosystem.
- Autonomous Vehicles: Enables cars to collaboratively learn from diverse driving experiences and sensor data, improving navigation, object detection, and safety features without centralizing sensitive location or behavioral data.
- Telecommunications: Optimizes network performance, predicts user behavior, and develops personalized services by training models on device usage data from millions of smartphones, preserving user privacy.
The retail sector can also benefit immensely, using federated learning to build more precise recommendation engines and optimize supply chains based on localized customer purchasing patterns, without having to pool sensitive consumer data. This allows for hyper-personalized experiences while respecting individual privacy preferences.
The widespread adoption of federated learning will not only drive innovation but also build greater trust in AI systems. By demonstrating a clear commitment to data privacy and responsible AI development, industries can foster stronger relationships with their customers and stakeholders, paving the way for a more ethical and efficient AI-driven future.
| Key Aspect | Brief Description |
|---|---|
| Data Privacy | Trains AI models on local data, preventing raw data centralization and enhancing security. |
| Cost Reduction | Distributes computation, reduces data transfer & storage needs, saving up to 15% by 2025. |
| Model Training | Only model updates are shared with a central server, not the sensitive raw data. |
| Industry Impact | Revolutionizes AI in healthcare, finance, and automotive by enabling secure, collaborative learning. |
Frequently Asked Questions About Federated Learning
The primary benefit is that raw, sensitive data never leaves its source device or server. Instead of centralizing data, only aggregated model updates are shared, significantly reducing the risk of data breaches and ensuring compliance with privacy regulations like GDPR and CCPA.
Federated learning reduces costs by minimizing data transfer bandwidth needs, distributing computational load to local devices, and decreasing the necessity for massive centralized data storage. This can lead to substantial savings, estimated around 15% by 2025 for AI model training.
While federated learning is highly versatile, its application varies depending on the model and data distribution. It’s particularly effective for deep learning models and scenarios with abundant decentralized data. Adaptations may be needed for highly complex or highly sequential data types.
Key challenges include handling data heterogeneity across clients, optimizing communication overhead between devices and the central server, and ensuring robustness against potential malicious participants or data poisoning attempts. Ongoing research actively addresses these complex issues.
In healthcare, it enables collaborative research on sensitive patient data without privacy breaches. In finance, it enhances fraud detection and risk assessment by leveraging distributed transaction data. Both sectors will see more accurate AI models while maintaining strict regulatory compliance and customer trust.
Conclusion
The journey towards mastering federated learning is critical for the evolution of AI, offering a powerful blueprint for developing intelligent systems that are both highly effective and inherently privacy-preserving. As we move towards 2025, the strategic adoption of federated learning will not only mitigate the escalating concerns around data privacy but also deliver tangible economic benefits through reduced training costs. This paradigm shift empowers industries to unlock the full potential of their distributed data, fostering innovation and building unprecedented levels of trust in AI. By embracing these advanced strategies, organizations can navigate the complexities of the modern data landscape, ensuring that AI development is ethical, efficient, and truly transformative.





")